此前在讨论基于模板引擎的开发方式和 django-rest-framework 开发的异同时说过,django-rest-framework 开发和传统的开发方式没有什么不同,区别仅在于返回的数据格式不同而已。
在基于模板引擎的开发方式中,博客首页文章列表的视图函数可能是这样的:
from django.shortcuts import render
from .models import Post
def index(request):
post_list = Post.objects.all().order_by('-created_time')
return render(request, 'blog/index.html', context={'post_list': post_list})
在 django-rest-framework,代码逻辑是一样的,只是在最后返回结果时,返回资源序列化后的结果。
from rest_framework.decorators import api_view
from rest_framework.response import Response
from rest_framework import status
from .models import Post
from .serializers import PostListSerializer
@api_view(http_method_names=["GET"])
def index(request):
post_list = Post.objects.all().order_by('-created_time')
serializer = PostListSerializer(post_list, many=True)
return Response(serializer.data, status=status.200)
暂且忽略掉资源序列化器 PostListSerializer,我们接下来会实现它,先把注意力放在主体逻辑上。
首先,我们从 rest_framework.decorators 中导入了 api_view 装饰器,并用它装饰了 index 视图函数,使其成为一个 RESTful API 视图函数。
为什么需要这个视图函数装饰器呢?之前说过,django-rest-framework 为 API 的开发提供了丰富的功能,包括内容协商、认证和鉴权、限流等等。这些过程 django 默认的视图函数在处理 HTTP 请求时是没有提供的,而经过 api_view 装饰后的视图,则提供了上述全部功能。
不过我们这里并没有看到任何内容协商、认证和鉴权、限流代码逻辑和配置,这是为什么呢?原因隐藏在 Python 的装饰器魔法里,django-rest-framework 对于上述功能有一套默认的处理逻辑,因此我们不需要进行任何配置,仅需使用 api_view 装饰一个 django 视图函数,所有功能全部自动开启。
视图函数里我们先从数据库获取文章列表资源,然后使用序列化器对其进行序列化,序列化后的数据存在 data 属性里,我们把它传递给 HTTP 响应类 Response,并将这个响应返回。
注意这个 Response 是从 rest_framework.response 中导入的,它类似于 django 的 HTTPResponse 响应类。实际上,这个类是 django-rest-framework 对 django 的模板响应类(SimpleTemplateResponse)的拓展(具体的细节可以不用了解,只要知道 django 使用它来渲染模板并构造 HTTP 响应即可),通常在 RESTful API 的视图函数中我们都会返回这个类,而不是 django 的 HTTP 响应类。此外,通过传入 status 参数,指定 HTTP 响应的状态码。
小贴士
请了解常用的 HTTP 状态码。在 RESTful 架构中,客户端通过 HTTP 请求动词表征对资源的操作意图,而服务端则使用 HTTP 状态码表示资源操作的结果。常用状态码及其含义如下:
200:通常表示请求成功。
201:表示资源创建成功。
400:表示客户端请求错误。
401:没有提供身份认证信息
403:没有操作权限
404 :访问的资源不存在
405:不支持的 HTTP 请求方法
500:服务器内部错误
HTTP 请求和响应过程,django-rest-framework 已经帮我们处理。但是资源的序列化,框架是无法自动化完成的,框架提供了基本的序列化器,我们需要自定义序列化逻辑。所以,让我们来定义 PostListSerializer 序列化器,用它来序列化文章列表。
序列化器由一系列的序列化字段(Field)组成,序列化字段的作用是,在序列化资源时,将 Python 数据类型转为原始数据类型(通常为字符类型或者二进制类型),以便在客户端和服务端之间传递;反序列化时,将原始数据类型转为 Python 数据类型。在转换过程中,还会进行数据合法性的校验。
先来看一个简单的例子(摘自 django-rest-framework 官网示例),理解序列化器的工作原理和功能。假设我们有一个 Python 类 Comment:
from datetime import datetime
class Comment(object):
def __init__(self, email, content, created=None):
self.email = email
self.content = content
self.created = created or datetime.now()
comment = Comment(email='leila@example.com', content='foo bar')
根据 Comment 类 3 个属性的类型,定义一个序列化器,用于数据序列化和反序列化。我们在上一步教程的 交流的桥梁:评论功能 中介绍过表单(Form)的定义。实际上,django-rest-framework 序列化器的设计参考了 django 表单的设计。序列化器和表单也有很多相似功能,比如对输入数据进行校验等。序列化器的代码如下:
from rest_framework import serializers
class CommentSerializer(serializers.Serializer):
email = serializers.EmailField()
content = serializers.CharField(max_length=200)
created = serializers.DateTimeField()
自定义的序列化器都要继承 serializers.Serializer 基类,基类提供了数据序列化和反序列化的逻辑。根据被序列化对象的属性的数据类型,需要指定相应的序列化字段(Serializer Field)。django-rest-framework 提供了很多常用的序列化字段,例如本例中用于序列化 email 数据格式的 EmailField,用于序列化字符型数据格式的 CharField,用于序列化日期格式的 DateTimeField。在实际项目中,应该根据数据类型,选择合适的序列化字段。全部序列化字段,可以参考官方文档 Serializer fields。
有了序列化器,就可以将 Comment 对象序列化了,序列化器用法如下:
>>> serializer = CommentSerializer(comment)
>>> serializer.data
# 输出:
{'email': 'leila@example.com', 'content': 'foo bar', 'created': '2016-01-27T15:17:10.375877'}
首先将需要序列化的对象(comment)传入序列化器(CommentSerializer),构造一个序列化器对象(serializer),访问序列化器对象的 data 属性,就可以得到序列化后的数据。
被序列化对象序列化后的数据是一个扁平的 Python 字典,字典中的数据描述了这个对象资源。有了序列化生成的 Python 字典,我们就可以将字典数据进一步格式化为 JSON 字符串或者 XML 文档字符串,在客户端和服务端之间传输。试想,客户端服务端通常都通过 HTTP 协议传输数据,传输的数据只能是字符串或者二进制数据,不可能将一个 Python 的对象直接传递,这就是为什么要序列化的原因。一端接收到序列化的数据后,如果有需要,可以对数据进行反序列化,重新恢复为 Python 对象。
以上就是一个标准序列化器的定义。其关键点在于,根据被序列化对象属性的数据类型,选择合适的序列化字段。回顾我们在上一步教程的 交流的桥梁:评论功能 中对评论表单的定义,我们通过继承 ModelForm 定义了表单,而并没有显示地指定表单字段的类型。原因在于,对于 django 中的模型(Model),已经有了定义其数据类型的模型字段,因此 django 表单可以根据关联的模型,自动推测需要使用的表单字段,在背后帮我们完成表单字段的选择,简化了表单的定义。
和表单类似,django-rest-framework 的序列化器也可以根据关联的模型,自动检测被序列化模型各个属性的数据类型,推测需要使用的序列化字段,无需我们显示定义。此时,自定义的序列化器不再继承标准的 Serializer,而是继承其子类,ModelSerializer。
我们来编写文章(Post)模型的序列化器代码。按照习惯,序列化器的代码位于相应应用的 serializers.py 模块中,因此在 blog 应用下新建一个 serializers.py 文件,写上如下代码:
from rest_framework import serializers
from .models import Post
class PostListSerializer(serializers.ModelSerializer):
category = CategorySerializer()
author = UserSerializer()
class Meta:
model = Post
fields = [
'id',
'title',
'created_time',
'excerpt',
'category',
'author',
'views',
]
使用 ModelSerializer 时,只需要在序列化器的内部类 Meta 中指定关联的模型,以及需要序列化的模型属性,django-rest-framework 就会根据各个属性的数据类型,自动推测需要使用的系列化字段,从而生成标准的序列化器。事实上,我们可以来看一下 django-rest-framework 最终生成的序列化器长什么样子:
class PostListSerializer():
id = IntegerField(label='ID', read_only=True)
title = CharField(label='标题', max_length=70)
created_time = DateTimeField(label='创建时间', required=False)
excerpt = CharField(allow_blank=True, label='摘要', max_length=200, required=False)
category = CategorySerializer()
author = UserSerializer()
还需要注意一点,title、created_time、views 这些属性都是原始的数据类型(字符型、日期型、整数类型)。而对于文章关联的 category、author,它们本身也是一个对象,django-rest-framework 就无法推测该使用什么类型的系列化字段来序列化它们了。所以这里我们按照标准序列化器的定义方式,将这两个属性的系列化字段分别定义为 CategorySerializer、UserSerializer,意思是告诉 django-rest-framework,请使用 CategorySerializer 和 UserSerializer 来序列化关联的 category 和 author。实际上,序列化器本身也是一个序列化字段。当然,CategorySerializer 和 UserSerializer 目前还不存在,我们来定义他们:
from django.contrib.auth.models import User
from .models import Category, Post
class CategorySerializer(serializers.ModelSerializer):
class Meta:
model = Category
fields = [
'id',
'name',
]
class UserSerializer(serializers.ModelSerializer):
class Meta:
model = User
fields = [
'id',
'username',
]
class PostListSerializer(serializers.ModelSerializer):
# ...
再来回顾一下我们的 API 视图函数代码:
@api_view(http_method_names=["GET"])
def index(request):
post_list = Post.objects.all().order_by('-created_time')
serializer = PostListSerializer(post_list, many=True)
return Response(serializer.data, status=status.HTTP_200_OK)
注意这里 PostListSerializer 的用法,构造序列化器时可以传入单个对象,序列化器会将其序列化为一个字典;也可以传入包含多个对象的可迭代类型(这里的 post_list 是一个 django 的 QuerySet),此时需要设置 many 参数为 True 序列化器会依次序列化每一项,返回一个列表。
给 api_view 装饰器传入 http_method_names 参数指定允许访问该 API 视图的 HTTP 方法。
现在我们已经有了视图函数,最后,我们需要给这个视图函数绑定 URL,在 blog 应用下的 urls.py 中加入绑定的代码:
path('api/index/', views.index)
启动开发服务器,打开浏览器访问 http://127.0.0.1:8000/api/index/,可以看到接口返回了文章列表 JSON 格式的数据(默认为 JSON)。
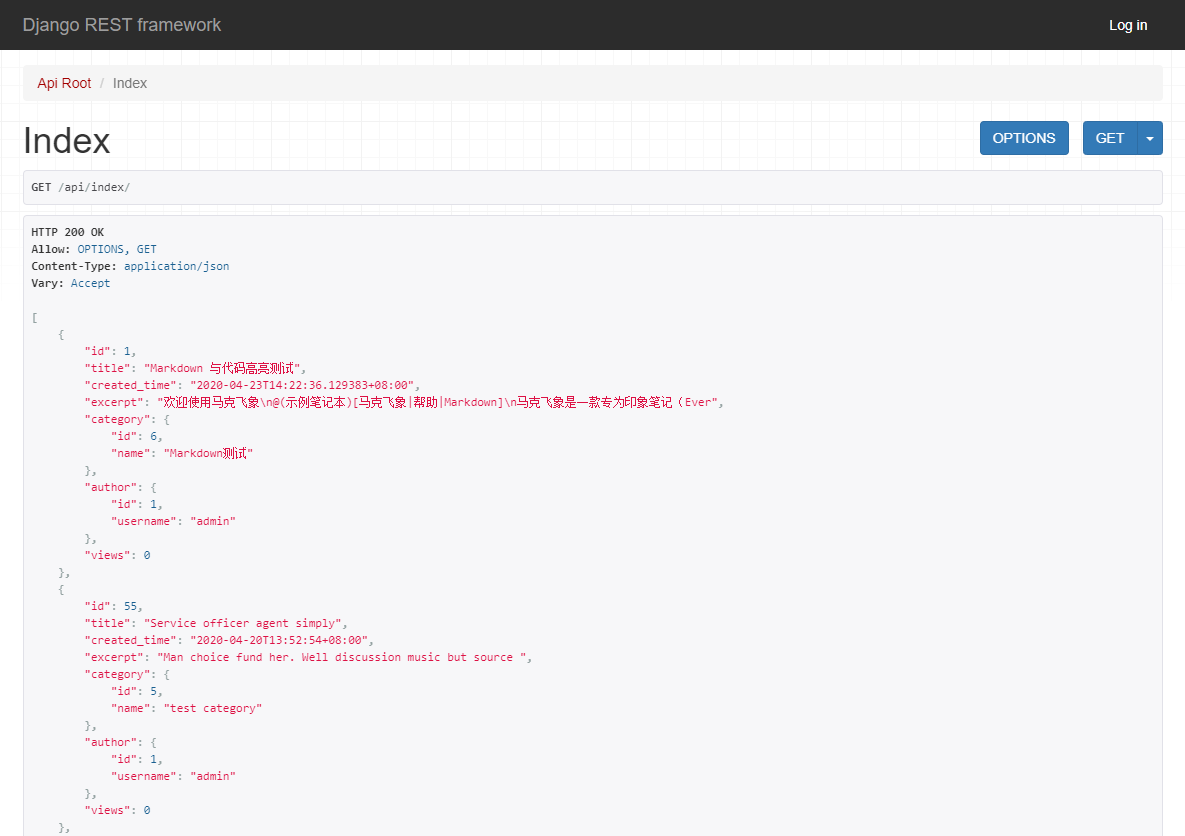
目前来说,这个接口其实作用不大。不过在后续的教程中,我们学习前端框架 Vue,那个时候,RESTful API 就有了它的用武之地了。
回顾一下 index API 视图函数的基本逻辑:
- 从数据库取数据
- 构造序列化器并将取出的数据序列化
- 返回响应
这其实是访问序列型的资源比较常见的逻辑,我们知道,django 专门为这种在 Web 开发中常用的逻辑提供了一系列基于类的通用视图,以提高代码的复用性和减少代码量。只是 django 的通用视图适用于基于模板引擎的开发方式,同样的,django-rest-framework 也提供了专门针对 RESTful API 开发过程中常用逻辑的类视图通用函数。接下来,让我们使用 django-rest-framework 提供的通用类视图,将首页 API 的视图函数改为类视图。
-- EOF --

感谢博主
博主是不是忘了写配置blog目录下的
urls.py了?drf真是折腾人🤷🏻♂️
在文章中应该有提了吧?
Field name
viewsis not valid for modelPost.这是怎么回事
看看 Post 里面定义了 views 这个属性吗?
测试
感谢博主
继续等更新
期待讲评论区怎么做