在 django 博客教程中,我们使用了 django-haystack 和 Elasticsearch 进行文章内容的搜索。django-haystack 默认返回的搜索结果是一个类似于 django QuerySet 的对象,需要配合模板系统使用,因为未被序列化,所以无法直接用于 django-rest-framework 的接口。当然解决方案也很简单,编写相应的序列化器将返回结果序列化就可以了。
但是,通过之前的功能我们看到,使用 django-rest-framework 是一个近乎标准化但又枯燥无聊的过程:首先是编写序列化器用于序列化资源,然后是编写视图集,提供对资源各类操作的接口。既然是标准化的东西,肯定已经有人写好了相关的功能以供复用。此时就要发挥开源社区的力量,去 GitHub 使用关键词 rest haystack 搜索,果然搜到一个 drf-haystack 开源项目,专门用于解决 django-rest-framework 和 haystack 结合使用的问题。因此我们就不再重复造轮子,直接使用开源第三方库来实现我们的需求。
既然要使用第三方库,第一步当然是安装它,进入项目根目录,运行:
$ pipenv install drf-haystack
由于需要使用到搜索功能,因此需要启动 Elasticsearch 服务,最简单的方式就是使用项目中编排的 Elasticsearch 镜像启动容器。
项目根目录下运行如下命令启动全部项目所需的容器服务:
$ docker-compose -f local.yml up --build
启动完成后运行 docker ps 命令可以检查到如下 2 个运行的容器,说明启动成功:
hellodjango_rest_framework_tutorial_local
hellodjango_rest_framework_tutorial_elasticsearch_local
接着创建一些文章,以便用于搜索测试,可以自己在 admin 后台添加,当然最简单的方法是运行项目中的 fake.py 脚本,批量生成测试数据:
$ docker-compose -f local.yml run --rm hellodjango.rest.framework.tutorial.local python -m scripts.fake
测试文章生成后,还要运行下面的命令给文章的内容创建索引,这样搜索引擎才能根据索引搜索到相应的内容:
$ docker-compose -f local.yml run --rm hellodjango.rest.framework.tutorial.local python manage.py rebuild_index
# 输出如下
Your choices after this are to restore from backups or rebuild via the `rebuild_index` command.
Are you sure you wish to continue? [y/N] y
Removing all documents from your index because you said so.
All documents removed.
Indexing 201 文章
GET /hellodjango_blog_tutorial/_mapping [status:404 request:0.005s]
注意
如果生成索引时看到如下错误:
elasticsearch.exceptions.ConnectionError: ConnectionError(
: Failed to establish a new connection:
[Errno -2] Name does not resolve) caused by: NewConnectionError(: Failed to establish a new connection: [Errno -2] Name does not resolve) 这是由于项目配置中 Elasticsearch 服务的 URL 配置出错导致,解决方法是进入 settings/local.py 配置文件中,将搜索设置改为下面的内容:
HAYSTACK_CONNECTIONS['default\']['URL'] = 'http://elasticsearch.local:9200/'
因为这个 URL 地址需和容器编排文件 local.yml 中指定的容器服务名一致 Docker 才能正确解析。
现在万事具备了,数据库中已经有了文章,搜索服务已经有了文章的索引,只需要等待客户端来进行查询,然后返回结果。所以接下来就进入到 django-rest-framework 标准开发流程:定义序列化器 -> 编写视图 -> 配置路由,这样一个标准的搜索接口就开发出来了。
先来定义序列化器,粗略过一遍 drf-haystack 官方文档,依葫芦画瓢创建文章(Post) 的 Serializer
blog/serializers.py
from drf_haystack.serializers import HaystackSerializerMixin
class PostHaystackSerializer(HaystackSerializerMixin, PostListSerializer):
class Meta(PostListSerializer.Meta):
search_fields = ["text"]
根据官方文档的介绍,为了复用已经定义好用于序列化文章列表的序列化器,我们直接继承了 PostListSerializer,同时我们还混入了 HaystackSerializerMixin,这是 drf-haystack 的混入类,提供搜索结果序列化相关的功能。
另外内部类 Meta 同样继承 PostListSerializer.Meta,这样就无需重复定义序列化字段列表 fields。关键的地方在这个 search_fields,这个列表声明用于搜索的字段(通常都定义为索引字段),我们在上一部教程设置 django-haystack 时,文章的索引字段设置的名字叫 text,如果对这一块有疑惑,可以简单回顾一下 Django Haystack 全文检索与关键词高亮 中的内容。
然后编写视图集,需继承 HaystackViewSet:
blog/views.py
from drf_haystack.viewsets import HaystackViewSet
from .serializers import PostHaystackSerializer
class PostSearchView(HaystackViewSet):
index_models = [Post]
serializer_class = PostHaystackSerializer
这个视图集非常简单,只需要通过类属性 index_models 声明需要搜索的模型,以及搜索结果的序列化器就行了,剩余的功能均由 HaystackViewSet 内部替我们实现了。
最后是在路由器中注册视图集,自动生成 URL 模式:
blogproject/urls.py
router = routers.DefaultRouter()
router.register(r"search", blog.views.PostSearchView, basename="search")
搞定了!一套标准化的 django-restful-framework 开发流程,不过大量工作已由 drf-haystack 在背后替我们完成,我们只写了非常少量的代码即实现了一套搜索接口。
来看看搜索效果。我们启动 Docker 容器,在浏览器输入如下格式的 URL:
http://127.0.0.1:8000/api/search/?text=key-word
将 key-word 替换为需要搜索的关键字,例如将其替换为 markdown,测试集数据中得到的搜索结果如下:

搜索结果符合预期,但略微有一点不太好的地方,就是没有高亮的标题和摘要,我们希望将来显示的结果应该是下面这样的,因此返回的数据必须支持这样的显示:

关键词高亮的实现原理其实非常简单,通过解析整段文本,将搜索关键词替换为由 HTML 标签包裹的富文本,并给这个包裹标签设置 CSS 样式,让其显示不同的字体颜色就可以了。
了解其原理后当然就是实现其功能,不过 django-haystack 已经为我们造好了轮子,而且在上一部教程的 Django Haystack 全文检索与关键词高亮,我们还对默认的高亮辅助类进行了改造,优化了文章标题被从关键字位置截断的问题,因此我们使用改造后的辅助类来对需要高亮的结果进行处理。
需要高亮的其实是 2 个字段,一个是 title、一个是 body。而 body 我们不需要完整的内容,只需要摘出其中一部分作为搜索结果的摘要即可。这两个功能,辅助类均已经为我们提供了,我们只需要调用所需的方法就行。
注意到这里我们需要对 title、body 两个字段进行高亮处理,其基本逻辑其实就是接收 title、body 的值作为输入,高亮处理后再输出。回顾一下序列化器的序列化字段,其实也是接收某个字段的值作为输入,对其进行处理,将其转化为可序列化的结果后输出,和我们需要的逻辑很像。但是,django-rest-framework 并没有提供这些比较个性化需求的序列化字段,因此接下来我们接触 drf 的一点高级用法——自定义序列化字段。
自定义序列化字段其实非常的简单,基本流程分两步走:
- 从 drf 官方提供的序列化字段中找一个数据类型最为接近的作为父类。
- 重写
to_representation方法,加入自己的序列化逻辑。
以我们的需求为例。因为 title、body 均为字符型,因此选择父类序列化字段为 CharField,定义一个 HighlightedCharField 字段如下:
from .utils import Highlighter
class HighlightedCharField(CharField):
def to_representation(self, value):
value = super().to_representation(value)
request = self.context["request"]
query = request.query_params["text"]
highlighter = Highlighter(query)
return highlighter.highlight(value)
django-rest-framework 通过调用序列化字段的 to_representation 方法对输入的值进行序列化,这个方法接收的第一个参数就是需要序列化的值。在我们自定义的逻辑中,首先调用父类 CharField 的 to_representation 方法,父类序列化的逻辑是将任何输入的值都转为字符串;接着我们从 context 属性中取得 request 对象,这个对象就是视图中的 HTTP 请求对象,但是因为 django 中 request 对象无法像 flask 那样从全局获取,因此 drf 在视图中将其保存在了序列化器和序列化字段的 context 属性中以便在视图外访问;获取 request 对象的目的是希望获取查询的关键字,query_params 属性是一个类字典对象,用于记录来自 URL 的查询参数,例如我们之前测试查询功能时调用的 URL 为 /api/search/?text=markdown,所以 query_params 保存了 URL 中的查询参数,将其封装为一个类字段对象 {"text": "markdown"},这里 text 的值就是查询的关键字,我们将它传给 Highlighter 辅助类,然后调用 highlight 方法将需要序列化的值进行进一步的高亮处理。
序列化字段定义好后,我们就可以在序列化器中用它了:
class PostHaystackSerializer(HaystackSerializerMixin, PostListSerializer):
title = HighlightedCharField()
summary = HighlightedCharField(source="body")
class Meta(PostListSerializer.Meta):
search_fields = ["text"]
fields = [
"id",
"title",
"summary",
"created_time",
"excerpt",
"category",
"author",
"views",
]
title 字段原本使用默认的 CharField 进行序列化,这里我们重新指定为自定义的 HighlightedCharField,这样序列化后的值就是高亮的格式。
summary 是我们新增的字段,注意我们序列化的对象是文章 Post,但这个对象是没有 summary 这个属性的,但是 summary 其实是对属性 body 序列化后的结果,因此我们通过指定序列化化字段的 source 参数,指定值的来源。
最后别忘了在 fields 中申明全部序列化的字段,主要是把新增的 summary 加进去。
来看看改进后的搜索效果:
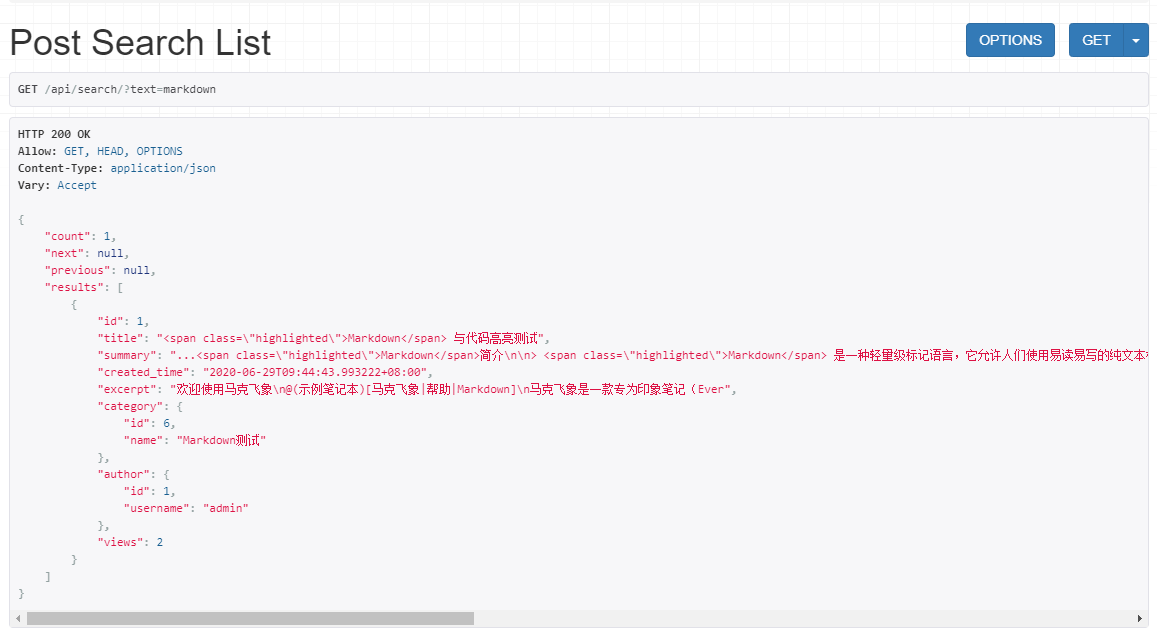
注意观察返回的 title 和 summary,我们搜索的关键词是 markdown,可以看到所有 markdown 关键字都被包裹了一个 span 标签,并且设置了 class 属性为 highlighted,只要设置好 css 样式,页面所有的 markdown 关键词就会显示不同的颜色,从而实现搜索关键词高亮的效果了。
当然,我们现在并没有实际用到这个特性,下一部教程我们将使用 Vue 来开发博客,到时候调用搜索接口拿到搜索结果后就会实际用到了。
-- EOF --
博主,请问Elasticsearch服务不用docker的话,要怎么启动?
博主这段代码稍微有些小问题,
.utils和CharField从哪来的没写上去,虽然跟文字一起辅助看最终能看懂,但是这里还是记录一下另外经过测试,安装好
drf-haystack,根据django博客教程设置好HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'后,运行完faker脚本后不需要重建索引了,haystack已经实时更新好了与博主同为django爱好者,我也基于django搭建了博客,渴望与博主互换友链。一起交流学习。本博客地址:https://oneisall.top
请加一下我的友链。
你好,本站已添加贵站友链。
好像并未在 https://oneisall.top/util/category/friend/ 中看到?
因博主回复消息过于滞后,友链我暂时隐藏了。建议博主弄个邮件通知吧。你的友链已显示。
嗯嗯,已加。
博主,催更,急需,正准备学习drf,没找到全栈教程啊
期待中.....